四个优化,火山引擎ByteHouse提升ClickHouse实时计算能力
近日,火山引擎数智平台VeDI与DataFun联合举办以“OLAP计算引擎”为主题的直播活动,来自火山引擎数智平台VeDI的产品专家从技术选型、能力分析、性能优化以及应用场景落地多个角度,介绍火山引擎ByteHouse如何基于ClickHouse实现实时计算能力升级。
据介绍,火山引擎ByteHouse来源于字节跳动多年内部沉淀。由于场景越来越丰富以及数据分析需求增长,业务对于实时数仓的要求也越来越高。首先是数据体量大以及不断增长的问题。早在2019 年,字节内部每天新增的数据量就达到了100TB。其次,在海量数据基础上,由于数据类型多样(包括批式数据和流式数据)、查询需求多样、交互式分析复杂,数据引擎需要具备灵活性。目前,行业Redis、 SparkSQL 等开源方案可以从不同角度满足上述两个需求,但是维护多个开源数据库将导致成本高,选择一款可以避免成本无限扩展的计算引擎成为字节数据研发首要考虑的问题。
ClickHouse性能高、灵活性强,且主要依赖磁盘、成本相对可控,成为字节跳动内部计算引擎的首选。但原生 ClickHouse 能力难以支持 upset 、实时数据更新等一些场景,在很多层面有局限性,例如:
· 单表性能强劲,但多表能力局限,且对标准 SQL 兼容性低。
· 缺乏成熟运维管理工具,运维复杂程度高。
· ClickHouse 为 MPP 架构(存算一体架构),性能强,但横向扩容成本非常高、数据隔离性差。
ByteHouse产品专家在直播中介绍到,“为了解决以上问题,我们主要从4个方向进行优化,让OLAP引擎能力、性能、运维、架构进一步升级。”
第一,丰富的自研表引擎,实现OLAP引擎能力进化。 ByteHouse 弥补了ClickHouse表引擎的不足,并衍生出全新的表引擎,包括使高可用表引擎、实时数据引擎、Unique 引擎、Bitmap 引擎。以Unique 引擎为例,它解决了社区版 ReplacingMergeTree 实时更新延迟问题,真正做到实时 upset。
第二,新增优化器、字典、索引支持能力,实现OLAP引擎性能进化。ClickHouse在多表场景中性能存在缺陷,而ByteHouse 通过自研CBO 和 RBO(基于代价和基于规则的优化器),支持了多层嵌套的下推、Join 子查询的下推、Join-Reorder、Bucket Join、Runtime Filter 等优化器特性,做到 TPC-DS 的性能可以达到 99 条sql100%覆盖,极大提升多表场景下的性能。另外,ByteHouse还支持了全局字典以及更多索引,如 Bitmap index,让查询效率更快。
第三, 自动化、可视化,实现OLAP引擎运维进化。ByteHouse 提供标准化运维、集群健康度检测、问题发生时的诊断工具,帮助运维人员提高效率。例如,集群健康度的检测工具,类似于集群的实时巡检,能够报告当前集群状态、出现了什么问题、问题如何解决,最大程度把问题前置化,降低运维风险。从效果上看, 18000 个节点只需要不到 10 个运维人员来支持。
第四, 存算分离,实现OLAP引擎架构进化。ByteHouse推出了 MPP 2. 0 即存算分离架构。一方面, 存算分离可以更好实现资源隔离,每一个计算任务都会提交到不同的计算资源中,做到用户之间互不影响,还能灵活扩容、缩容存储计算资源;另一方面,存算分离能做到真正云原生(Cloud native),ByteHouse 存储层既支持 HDFS,也支持 S3 对象或者其他的对象存储,实现云原生部署。
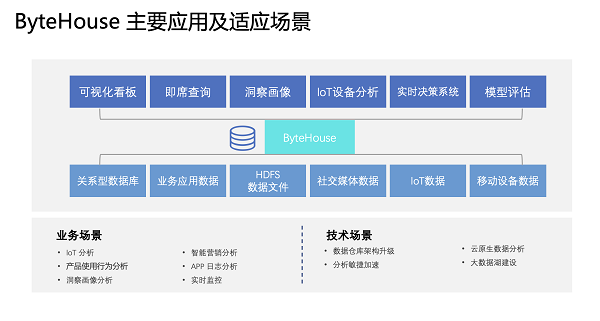
目前,ByteHouse已经在行为分析、精准营销、实时监控等业务场景中落地。以实时监控为例,很多互联网APP有线上运营活动、直播电商等业务,数据实时性格外重要。数据从生产到展现在大屏上,延迟往往要控制在分钟级甚至秒级以内。而ByteHouse高吞吐性能、查询性能,使数据从输入端到输出端的流程达到秒级。在数据保障层面,ByteHouse 也能精细到Exactly once 的语义,保证数据不丢失、不重复,最终达到数据高效存储、准确查询。(作者:唐柏豪)
相关文章
- 火山引擎DataTester:AB实验平台未来演进趋势是怎样的?
- 天龙Denon PerL系列全国巡展,聆听高定HiFi原音
- 预售价格25.8万起,馈电才4毛钱,问界新M7大五座便宜又好用
- 麒盛科技总经理黄小卫:深度布局智能睡眠领域 多维度推进国民睡眠健康产业革新
- 全新门派“万灵山庄”首曝 《剑网3》十四周年发布会全回顾
- 新一代生产力工具“夸克扫描王App”上线 AI大模型让扫描“提质增效”
- 敢向前,自有风 | 三头六臂八周年,合作共赢,实现全局共同富裕
- 怪不得斐色耐化妆镜是呼声最高的化妆镜!原来是因为....
- 天龙PerL系列产品新固件升级:拥抱更精彩的声音世界
- 软件定义汽车时代来临,喜马拉雅等车载音频平台以四大能力助推汽车生态持续增值
- 阿尔法蛋AI词典笔T20旗舰版重磅升级! 英汉双语作文随时随地改
- 首屈一指的大屏体验 三星Galaxy Tab S9系列焕新品质生活
- 云鲸J4自研零缠绕滚刷、机器人轻集尘,引领清洁机器人行业发展新趋势
- 瑞数信息入选专用Bot管理代表厂商 Gartner《创新洞察报告:面向IAM的Bot管理》
- 奥维云网2023数字生态大会集成厨电创领峰会圆满落幕
- 客厅专用投影仪什么牌子好?推荐一款客厅专用投影仪当贝X5,ALPD激光白天也清晰
热门教程
Win11每次开机会检查tpm吗?Win11每次开机是否会检查tpm详情介绍
2系统之家装机大师怎么用?系统之家装机大师使用教程
3Win11正式版怎么安装安卓APK应用?Win11安装安卓APK文件方法
4Win10 21H1更新KB5003637后任务栏不能在底部显示怎么办?
5Win11电脑下载的文件被自动删除怎么办?
6Win11资源管理器的样式如何切换?Win11资源管理器样式切换方法
7Win11蓝屏怎么修复?win11蓝屏修复教程
8老电脑怎么装win11系统?老电脑一键升级Win11系统教程
9Win11正式版如何固定“此电脑”到任务栏?
10Win10和Win11哪个好用?Win10和Win11区别介绍
装机必备 更多+
重装教程
大家都在看
电脑教程专题 更多+