字节与浙大联合推多模态大语言模型Vista-LLaMA 可解读视频内容
Vista-LLaMA 在处理长视频内容方面的显著优势,为视频分析领域带来了新的解决框架。
近年来,大型语言模型如 GPT、GLM 和 LLaMA 等在自然语言处理领域取得了显著进展,基于深度学习技术能够理解和生成复杂的文本内容。然而,将这些能力扩展到视频内容理解领域则是一个全新的挑战 —— 视频不仅包含丰富多变的视觉信息,还涉及时间序列的动态变化,这使得大语言模型从视频中提取信息变得更为复杂。
面对这一挑战,字节跳动联合浙江大学提出了能够输出可靠视频描述的多模态大语言模型 Vista-LLaMA。Vista-LLaMA 专门针对视频内容的复杂性设计,能够有效地将视频帧转换为准确的语言描述,从而极大地提高了视频内容分析和生成的质量。

论文主页:https://jinxxian.github.io/Vista-LLaMA/
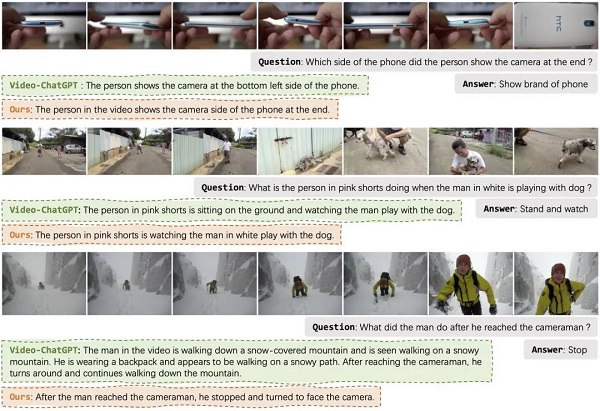
图 1
技术创新路径
现有多模态视觉与语言模型在处理视频内容时,通常将视频帧转化为一系列的视觉 token,并与语言 token 结合以生成文本。然而,随着生成文本长度的增加,视频内容的影响往往逐渐减弱,导致生成的文本越来越多地偏离原视频内容,产生所谓的 “幻觉” 现象。
Vista-LLaMA 通过创新的方式处理视频和文本间的复杂互动,突破了传统视频语言模型的限制。Vista-LLaMA 的核心创新在于其独特的视觉与语言 token 处理方式。不同于其他模型,它通过维持视觉和语言 token 间的均等距离,有效避免了文本生成中的偏差,尤其是在长文本中更为显著。这种方法大幅提高了模型对视频内容的理解深度和准确性。
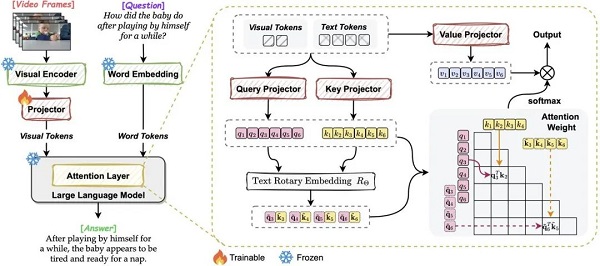
图 2
Vista-LLaMA 采用了一种改良的注意力机制 —— 视觉等距离 token 注意力(EDVT),它在处理视觉与文本 token 时去除了传统的相对位置编码,同时保留了文本与文本之间的相对位置编码。EDVT 机制通过特定的函数处理隐藏层输入,有效区分视觉 token 来源。
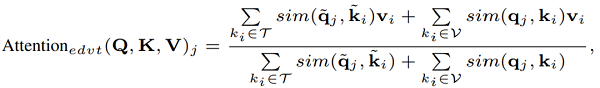
具体而言,它首先对输入进行查询、键和值的映射转换,接着对查询和键输入应用旋转位置编码(RoPE),分别计算带 RoPE 和不带 RoPE 的注意力权重。随后,根据视觉 token 的存在与否合并这两种注意力权重,通过 softmax 函数实现注意力的归一化,并最终通过基于注意力权重的线性映射更新表示,生成输出结果。这种创新使得多模态大语言模型能够更加关注视频的内容,尤其在复杂的视频场景中,能够有效地捕捉关键视觉元素,提升了文本生成的质量和相关性。

图 3
同时,该模型引入的序列化视觉投影器为视频中的时间序列分析提供了新的视角,它不仅能够处理当前视频帧,还能利用前一帧的信息,从而增强视频内容的连贯性和时序逻辑。
视觉投影器的作用是将视频特征映射到语言嵌入空间,以便大型语言模型融合和处理视觉与文本输入。如图 4 所示,早期的视觉投影器通常使用线性层或查询转换器(Q-Former)直接将帧特征转换为语言 token。然而,这些方法忽略了时间关系,限制了语言模型对视频的全面理解。Vista-LLaMA 中引入了序列化视觉投影器,它通过线性投影层编码视觉 token 的时间上下文,增强了模型对视频动态变化的理解能力,这对于提升视频内容分析的质量至关重要。
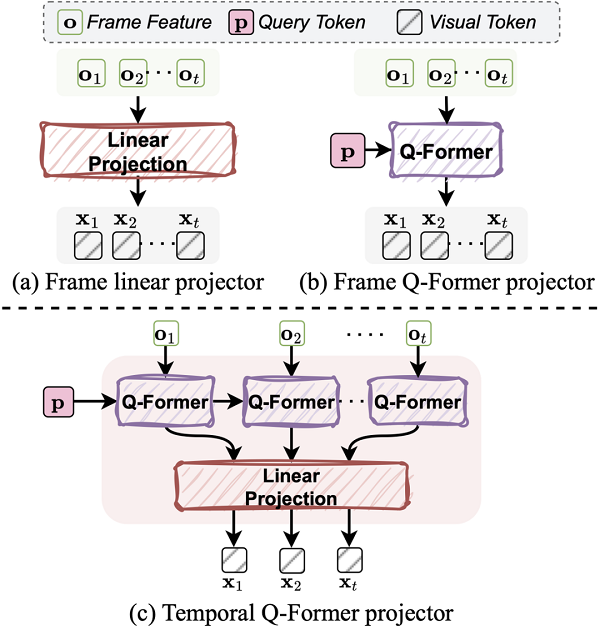
图 4
基准测试结果
Vista-LLaMA 在多个开放式视频问答基准测试中展现了卓越性能。它在 NExT-QA 和 MSRVTT-QA 测试中取得了突破性成绩,这两个测试是衡量视频理解和语言生成能力的关键标准。在零样本 NExT-QA 测试中,Vista-LLaMA 实现了 60.7% 的准确率。而在 MSRVTT-QA 测试中达到了 60.5% 的准确率,超过了目前所有的 SOTA 方法。这些成绩在行业中属于先进水平,显著超越了其他 SOTA 模型,如 Video-ChatGPT 和 MovieChat。
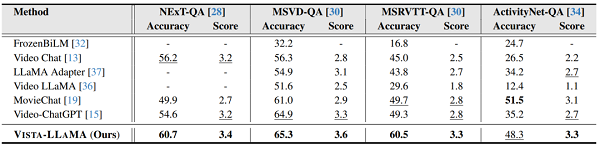
图 5
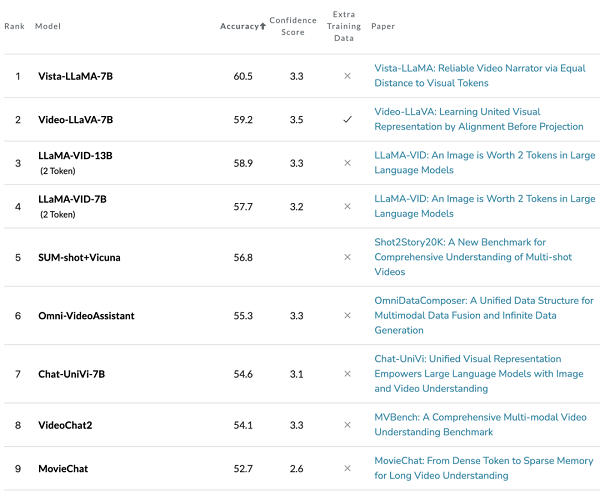
这些测试结果证明了 Vista-LLaMA 在视频内容理解和描述生成方面的高效性和精准性,Vista-LLaMA 能够准确理解和描述视频内容,显示了其强大的泛化能力。这些成绩不仅展示了 Vista-LLaMA 在理解复杂视频内容方面的能力,还证明了其在多模态语言处理领域的领先地位。
数据集:CineClipQA
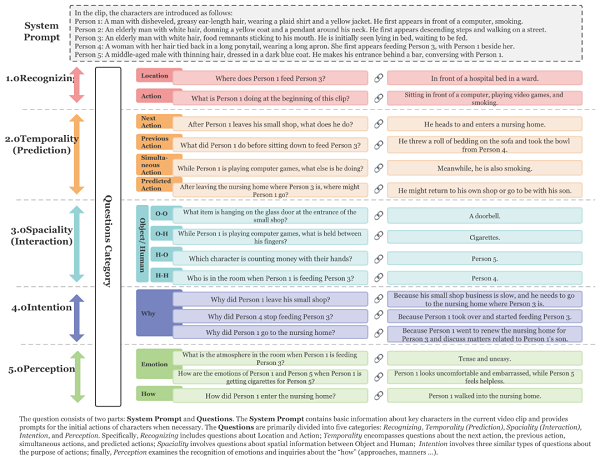
图 6
与 Vista-LLaMA 一同提出的还有 CineClipQA 新数据集。
CineClipQA 包含了 153 个精选视频片段,这些片段来自五部风格和叙事手法各异的电影。每个片段代表电影情节的一个或多个独特部分,并附有 16 个量身定制的问题,共计 2448 个问题。问题分为系统提示和问题两部分:
● 系统提示提供了当前视频片段中关键角色的基本信息,并在必要时为角色的初始行动提供提示。
● 问题主要分为五类:识别、时间性(预测)、空间性(互动)、意图和感知。具体来说,识别包括地点和行动的问题;时间性涉及下一个行动、之前的行动、同时发生的行动和预测行动的问题;空间性涉及物体与人之间的空间信息问题;意图涉及行动目的地三种相似问题;感知检查情感识别和询问 “如何”(方式、态度等)。
该研究还提供了所有 16 种类型的详细解释和相应案例。在 CineClipQA 数据集中,Vista-LLaMA 也表现出了卓越的性能。

图 7
简言之,Vista-LLaMA 在处理长视频内容方面的显著优势,为视频分析领域带来了新的解决框架,推动人工智能在视频处理和内容创作方面的发展,预示着未来多模态交互和自动化内容生成领域的广泛机遇。
更多详情,请访问项目页面 [https://jinxxian.github.io/Vista-LLaMA]。
关于字节跳动智能创作团队
智能创作团队是字节跳动音视频创新技术和业务中台,覆盖了计算机视觉、图形学、语音、拍摄编辑、特效、客户端、服务端工程等技术领域,借助字节跳动丰富的业务场景、基础设施资源和良好的技术协作氛围,实现了前沿算法 - 工程系统 - 产品全链路的闭环,旨在以多种形式向公司内部各业务线以及外部合作客户提供业界前沿的内容理解、内容创作、互动体验与消费的能力和行业解决方案。
目前,智能创作团队已通过字节跳动旗下的云服务平台火山引擎向企业开放技术能力和服务。(作者:彭傲晴)
相关文章
- 绿源S90三年质保续航不减,啥黑科技挑战行业首个整车全性能极寒测试?
- 三星电子推出 2024新品 Neo QLED、MICRO LED、OLED 和 Lifestyle产品,开启人工智能屏幕新时代,引领全新生活方式
- 2024超短焦投影仪哪款好?当贝U1亲测体验, 强力推荐
- 家居博主分享年货节客厅投影仪选购指南,当贝F6让观影体验更升级
- 智能体验升级!搭载安第斯大模型和全新小布的OPPO Find X7系列正式发布
- 大模型下场,360智慧生活“智助”三百六十行
- 步履不停,2023移动云“云”赋百业
- 超值狂欢购来袭 登录三星商城购Galaxy手机享多重好礼
- 最方便的大模型端口来了!通义千问入驻钉钉,提供文图视频等多模态服务
- 抖音发布2023年网暴治理年度盘点,持续与社会各界共同抵制网暴
- 三星The Serif画境艺术电视获“2023中国电子视像行业协会科技创新奖”
- 投影仪追剧怎么样?2024最适合打工人的卧室投影仪推荐
- 高性能轻薄本新标杆!ROG正式发布ROG幻14 Air及幻16 Air
- 新年优选 三星Galaxy Tab S9系列助职场更“晋”一步
- 2024年挑选客厅投影仪的秘诀:当贝F6投影仪质价比的新标杆
- 课堂同步听说 掌握又快又准 阿尔法蛋AI听说宝D1重磅上市
热门教程
Win11每次开机会检查tpm吗?Win11每次开机是否会检查tpm详情介绍
2系统之家装机大师怎么用?系统之家装机大师使用教程
3Win11任务栏空白怎么办?Win11任务栏空白解决办法
4Win11正式版怎么安装安卓APK应用?Win11安装安卓APK文件方法
5Win10 21H1更新KB5003637后任务栏不能在底部显示怎么办?
6Win10家庭版笔记本电脑怎么关闭Windows defender功能?
7Win11资源管理器的样式如何切换?Win11资源管理器样式切换方法
8Win11电脑下载的文件被自动删除怎么办?
9Win11蓝屏怎么修复?win11蓝屏修复教程
10Win11正式版如何固定“此电脑”到任务栏?
装机必备 更多+
重装教程
大家都在看
电脑教程专题 更多+