谷歌 AI 看不懂网友评论,会错意高达 30%,网友:你不懂我的梗
给你两句话,来品一下它们所蕴含的情感:“我真的会谢。”“听我说谢谢你,因为有你,温暖了四季……”

或许你会说,这很简单啊,不就是最近经常被玩的梗吗?但如果问问长辈,他们可能就是一副“地铁老人看手机”的模样了。
不过与流行文化之间有代沟这事,可不仅限于长辈们,还有 AI。这不,一位博主最近就 po 出了一篇分析谷歌数据集的文章,发现它对 Reddit 评论的情绪判别中,错误率竟高达 30%。

就比如这个例子:
我要向朋友怒表达对他的爱意。
谷歌数据集把它判断为“生气”。
还有下面这条评论:
你 TM 差点吓坏我了。
谷歌数据集将其判别为“困惑”。

网友直呼:你不懂我的梗。
人工智能秒变人工智障,这么离谱的错误它是怎么犯的?
断章取义它最“拿手”
这就得从他判别的方式入手了。谷歌数据集在给评论贴标签时,是把文字单拎出来判断的。我们可以看看下面这张图,谷歌数据集都把文字中的情绪错误地判断为愤怒。
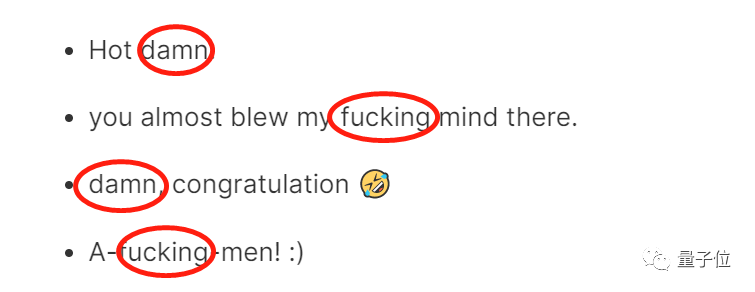
不如我们由此来推测一下谷歌数据集判别错误的原因,就拿上面的例子来说,这四条评论中均有一些“脏话”。
谷歌数据集把这些“脏话”拿来作为判断的依据,但如果仔细读完整个评论,就会发现这个所谓的“依据”只是用来增强整个句子的语气,并没有实际的意义。
网友们的发表的评论往往都不是孤立存在的,它所跟的帖子、发布的平台等因素都可能导致整个语义发生变化。
比如单看这条评论:
his traps hide the fucking sun.
单单依靠这个很难判断其中的情绪元素。但如果知道他是来自一个肌肉网站的评论,或许就不难猜出了,(他只是想称赞一下这个人的肌肉)。
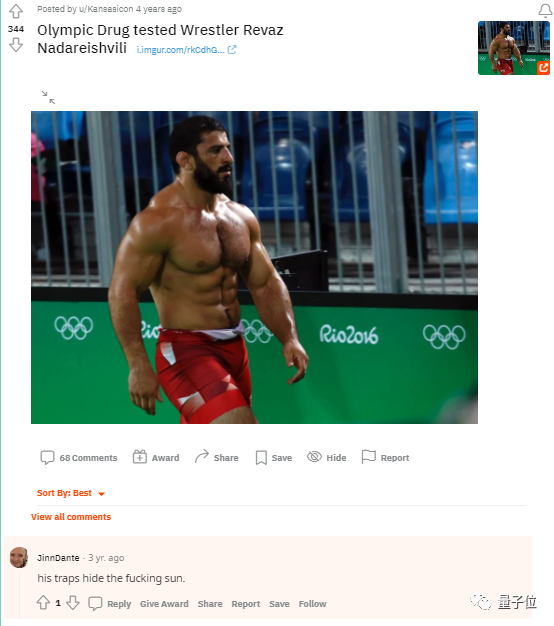
忽略评论的帖子本身,或者将其中某个情感色彩强烈的词语单拎出来判断其情绪元素都是不合理的。一个句子并不是孤立存在的,它有其特定的语境,其含义也会随着语境的变化而变化。
将评论放入完整的语境中去判断其情绪色彩,或许会大大提升判别的准确率。但造成 30% 这么高的失误率可不仅仅只是“断章取义”,其中还有更深层次的原因。
“我们的梗 AI 不懂”
除了语境会干扰数据集判别之外,文化背景也是一个非常重要的因素。
大到国家地区,小到网站社群都会有其内部专属的文化符号,这种文化符号圈层之外的人很难解读,这就造成了一个棘手的问题:若想更准确地判断某一社区评论的情绪,就得针对性地对其社区进行一些数据训练,深入了解整个社区的文化基因。
在 Reddit 网站上,网友评论指出“所有的评分者都是以英语为母语的印度人”。

这就导致会对一些很常见的习语、语气词及一些特定的“梗”造成误解。说了这么多,数据集判别失误率这么高的原因也就显而易见了。
但与此同时,提高 AI 判别情绪的精确度也有了清晰的方向。例如博主也在这篇文章中就给出了几条建议:
首先,在对评论贴标签时,得对他所处的文化背景有深刻地理解。以 Reddit 为例,要判断其评论的情绪色彩,要对美国的一些文化、政治理解透彻,并且还要能够迅速 get 到专属网站的“梗”;
其次,要测试标签对一些讽刺、习语、梗的判别是否正确,确保模型能够整整理解文本的意思;
最后,核查模型判断与我们真实判别,以做出反馈,更好地训练模型。
One More Thing
AI 大牛吴恩达曾发起过一项以数据为中心的人工智能运动。

将人工智能从业者的重点从模型 / 算法开发转移到他们用于训练模型的数据质量上。吴恩达曾说:
数据是人工智能的食物。
用于训练数据的好坏对于一个模型也至关重要,在新兴的以数据为中心的 AI 方法中,数据的一致性至关重要。为了获得正确的结果,需要固定模型或代码并迭代地提高数据质量。
……
最后,你觉得在提高语言 AI 判别情绪这件事上,还有什么方法呢?
欢迎在留言区讨论~
参考链接:
[1]https://www.reddit.com/r/MachineLearning/comments/vye69k/30_of_googles_reddit_emotions_dataset_is/[2]https://www.surgehq.ai/blog/30-percent-of-googles-reddit-emotions-dataset-is-mislabeled[3]https://mitsloan.mit.edu/ideas-made-to-matter/why-its-time-data-centric-artificial-intelligence
相关文章
- 智源“抄袭门”最新通报:2 处抄袭 4 处引用不规范,相关责任人均已主动离职
- 语言 AI 原来知道自己的回答是否正确!伯克利等高校新研究火了,网友:危险危险危险
- 苹果 M2 MacBook Air 已支持在欧洲和亚洲 Apple Store 零售店当日取货
- 苹果 M2 芯片版 MacBook Air 附赠匹配的 Apple Logo 贴纸,新增午夜和星光色
- 苹果 M2 MacBook Air 今日开售,首批订单现已交付给新西兰和澳大利亚客户
- 基准测试表明 M2 芯片版 MacBook Air 的 256GB SSD 速度较慢,苹果官方回应“实际性能甚至更快”
- 苹果 M2 MacBook Air 评测解禁:屏幕素质、扬声器更佳,GPU 性能大增
- 幸运用户已收到苹果 M2 芯片版 MacBook Air
- 效率提升 1200 倍,麻省理工开发出 AI 制药新模型
- 用户收到通知,苹果 M2 芯片版 Macbook Air 国行已开始发货
- 广汽埃安 AION Y PLUS 工信部申报,搭载 150kW 电动机
- 苹果 M2 MacBook Air 拆机预览:采用经典三段式电池,扬声器位于铰链处
- 惠普推出战 99 Air:12 代酷睿 + 2.5K 120Hz 高素质屏,6999 元起
- 谷歌子公司开发新款无人机,6 英里内可无压力送货
- 谷歌从 Android 移除大量 Fuchsia 相关代码,Starnix 项目新进展曝光